
多模态RAG系统
多模态的RAG相比于文本的RAG多了图片和表格等数据模态,能够给用户更丰富的问答体验,提高沟通效率。
下面从数据来源,数据解析,预处理,分块策略,数据库设计,索引策略,检索策略,生成策略,精准引用策略,评估方法,效果实测,项目局限和未来发展等方面介绍本项目。
项目特色:
①领域:垂直领域的论文问答。
②模态:支持检索相关的图片和表格,给回复以佐证。
③引用:自动添加合适的参考文献,可定位到原文的句子。
④效果:在RAGS上评估,各项指标均比较优秀。
数据来源
20年至2024.12.8的图情和计算机方向的舆情分析核心期刊论文。共近200篇。
数据解析
采用MinerU库对PDF文件解析,提取出图片,识别出表格、公式。最终得到图片文件,论文的MD文件。
MinerU集成了飞桨OCR、doclayout等多种pdf识别工具,功能丰富,且不依赖于大模型,成本低。
预处理
MinerU库解析后的MD文件内容仍然存在只有一级标题、内容中间空行或空白、中文标点成英文标点、表格、公式等问题,极大地影响了后续的分块和检索召回效果。因此,必须进行如下预处理:
①标题问题:由大模型完成标题修改,输出置信得分,人工检验得分低的部分。
②内容中的空行和空白问题:观察空行和空白的规律,撰写相关的方法处理。也可以由大模型完成。
③英文标点问题:考虑到小数点、英文单词的标点必须是英文的,先给这些标点替换为占位符,再对其余的(原本为中文标点)进行替换。最后再还原英文标点。利于后续中文递归分块。
④表格公式:解析后表格公式是在MD里,如果还要对这些进行分块,那可能一个表格或公式会分为两个块,影响大模型理解。因此正则提取出表格和公式,图片则有本地的路径,分别使用占位符替代。
分块策略
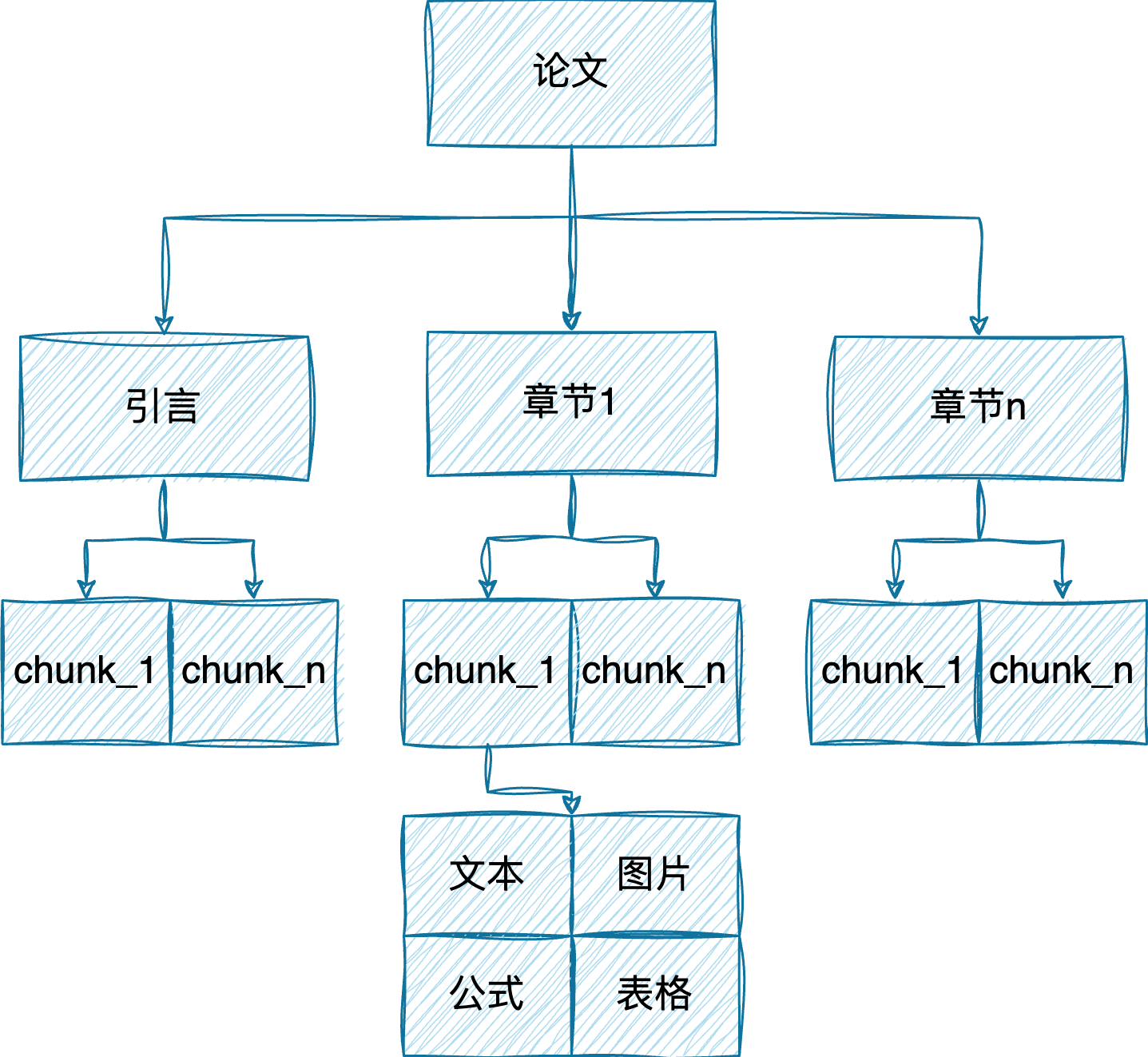
考虑到论文本身有比较好的结构,同时主流的向量模型的上下文窗口都在512左右,因此采用层级分块的策略。
对比chonkie和langchain的分块方法,后者的效果和在中文的适应性上更好,遂使用langchain的text_splitter进行分块。
第一级:章节级。按照不同标题的等级进行递归分块。MarkdownHeaderTextSplitter。这样切分出个最小章节的内容。
第二级:内容级。按照中文标点进行分割,设置chunk_size为500个字符。在细分chunk的同时尽可能保留语义信息。这部分还尝试过语义分块,但是大部分都分不出来,毕竟论文的每个章节的内容主题大致相同。
数据库设计
采用Infinity数据库。为什么不选择Milvus?
作为个人开发者,Infinity安装简单,速度快,支持融合搜索及多种数据类型输出,易用性更强。
由于是多模态的RAG,而且是论文场景,所以设计了五张表:
①论文表:包括论文id,题名等元数据。
②章节表:包括章节id,论文id,章节文本等章节级别的数据。
③chunk表:包括chunk的id,论文id,章节id,chunk文本等chunk级别的数据。
④图片表:包括图片的id,论文id,章节id,chunkid,图片路径等数据。
⑤表格表:包括表格的id,论文id,章节id,chunkid,表格内容等数据。
⑥公式表:包括公式的id,论文id,章节id,chunkid,公式内容等数据。
索引策略
秉承着要查询什么就在哪建索引的原则。
所以在chunk表上建立了BM25的全文索引和HNSW向量索引,在图片表上建立了向量索引。
进行数据入库,建立完毕所有的索引。
检索策略
目前仅支持文本格式的输入。
当用户输入查询后,首先进行改写,一种是优化问题,使其更专业,一种是直接给出虚拟文档。
用这两种文本对chunk表执行加权的混合检索,得到相应的chunk内容。
根据chunkid和图片、表格、公式表进行联结,得到每个chunk对应的文本、图片、表格和公式,将完整的chunk内容还原。图片这里是另外存储的。
将完整的chunk按照属于每个论文和章节的顺序排列,这样信息更连贯。
生成策略
采用的是LLM,因此不支持图片作为输入。
将检索到的chunk完整内容组织成上下文,由提示大模型这是MD文本,再传入用户的查询。调用大模型生成回复。
多轮对话涉及到生成回复和查询改写,让大模型明晰用户讨论的是什么话题。为了减少token数,查询改写只保留用户的问题,回复生成采用截断的方式。
精准引用策略
如果由大模型自动生成引用,耗时长且存在幻觉。
因此采用后处理的方式,先让大模型生成原始答案,再计算每个句子与每个参考文档的相似度,这部分采用重排模型完成。再得到参考文献中和该句子最相关的句子。
评估方法
使用Ragas进行评估。
整理了100个问题,由大模型生成回复,作为真实答案。
选取了context_recall、faithfulness、semantic_similarity三个指标。
①context_recall:评估成功检索的相关文档的数量。计算流程:分解真实答案中的每个声明,以确定它是否可以归因于检索到的上下文。在理想情况下,参考答案中的所有声明都应该归因于检索到的上下文。
②faithfulness:评估生成的答案在给定上下文中的事实一致性。计算流程:从生成的答案中确定一组声明。然后,这些声明中的每一个都与给定的上下文进行交叉检查,以确定是否可以从上下文中推断出来。
③semantic_similarity:评估生成的答案与真实答案之间的语义相似性(余弦相似度)。
结果:
| Indicator | Value |
|---|---|
| Context Recall | 0.4609 |
| Faithfulness | 0.7993 |
| Semantic Similarity | 0.8996 |
效果实测
为验证本论文RAG系统的可用性,与知网的华知大模型进行对比。
所有的查询均是在同一会话的多轮问答。
查询1:事理图谱的原理是什么?
知网结果的rag结果:
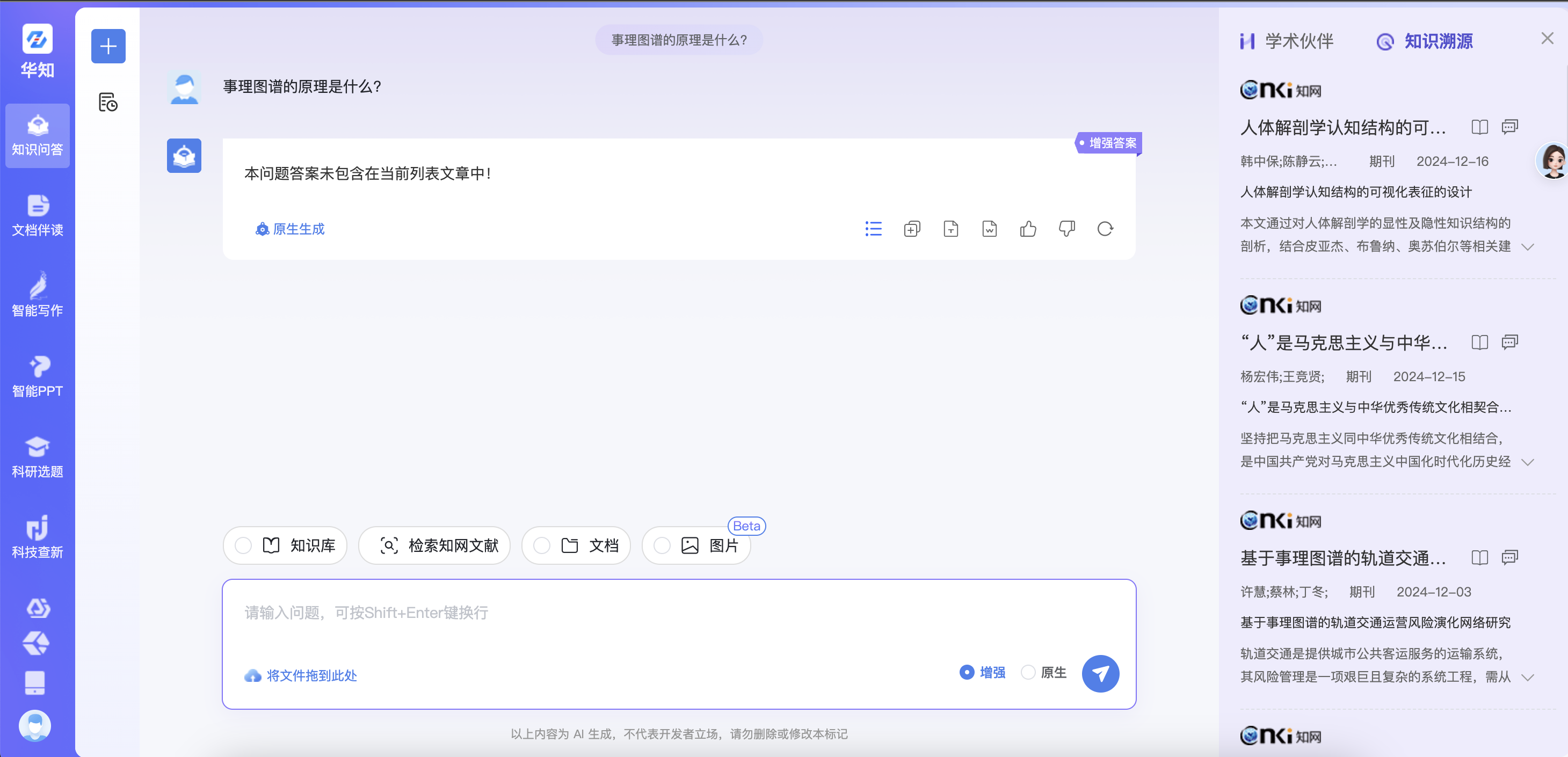
知网的原生结果:

本项目的结果:

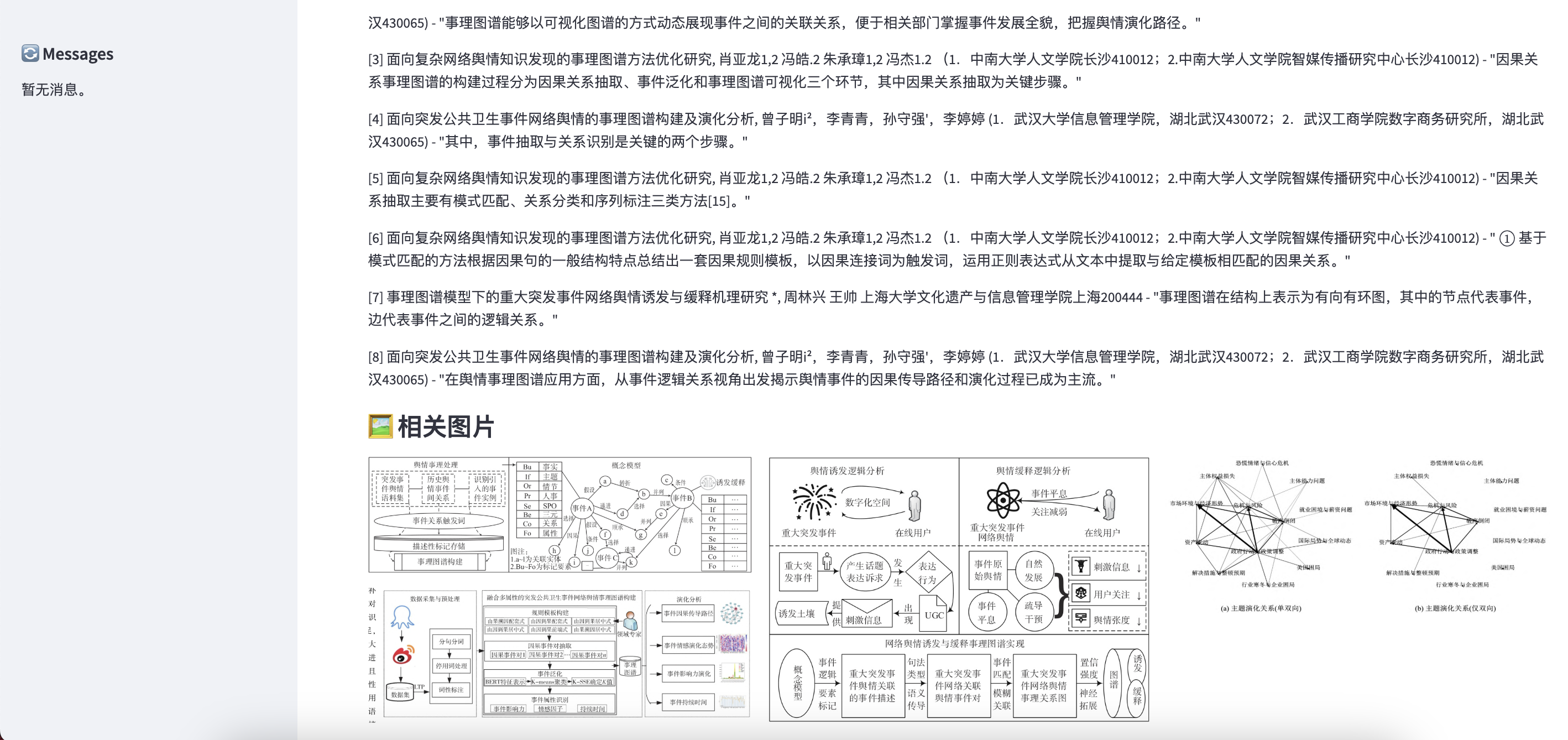
可以看到,知网的RAG没有输出任何东西,原生答案回答了定义。本项目的回答参考了许多论文的内容,回答的可理解性更强。
查询2:假设我要从头构建一个基于微博平台的事理图谱,该怎么做?请从数据来源,数据处理,图谱构建,图谱分析与解读等方面介绍
知网结果的rag结果:

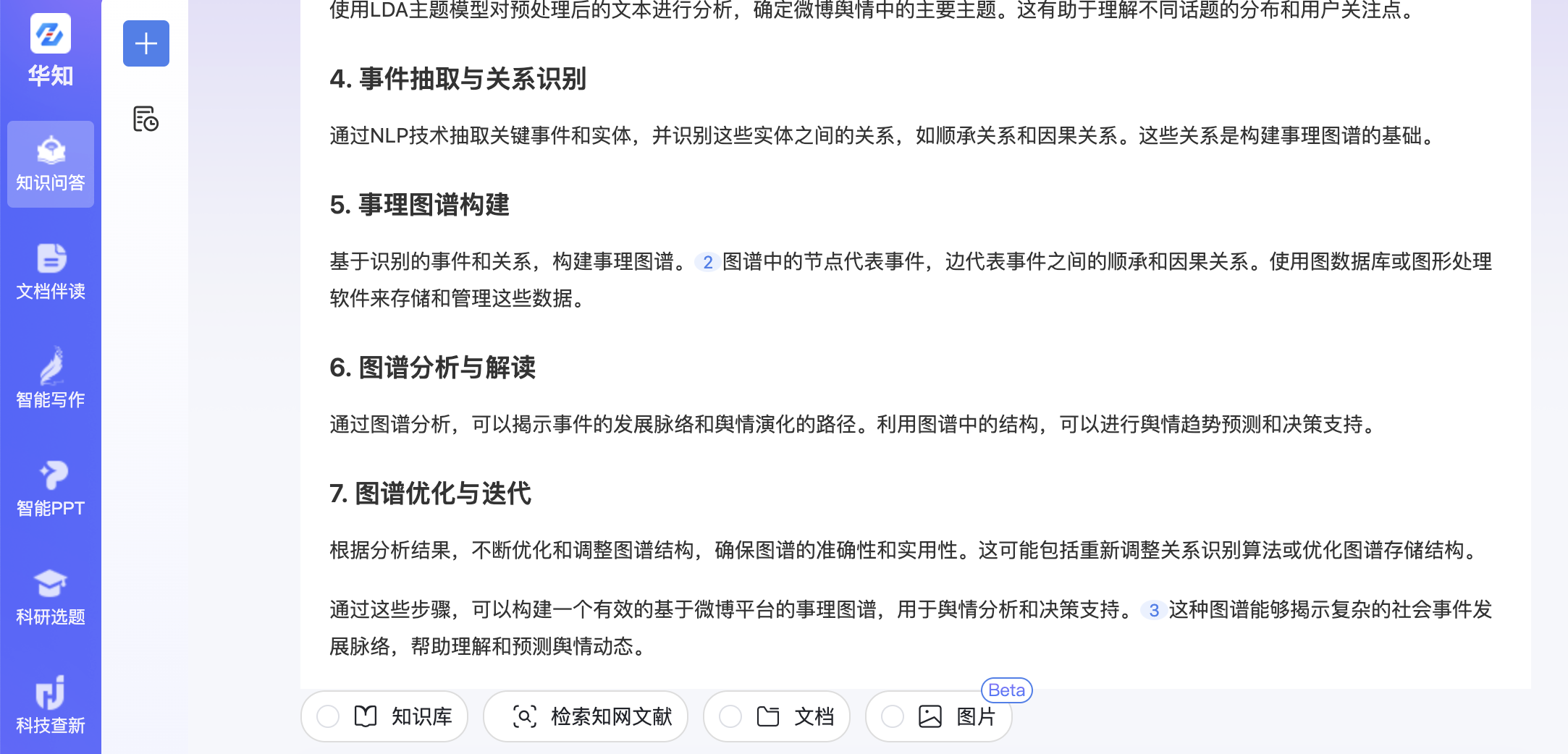
知网的原生结果:

本项目的结果:


可以看到,知网的RAG结果出现了幻觉,没有按照我查询的要求进行回复,原生结果的信息量太少。而本项目的结果显得更为充实和科学。
查询3:lda和bertopic主题分析的差异在哪?
知网结果的rag结果:
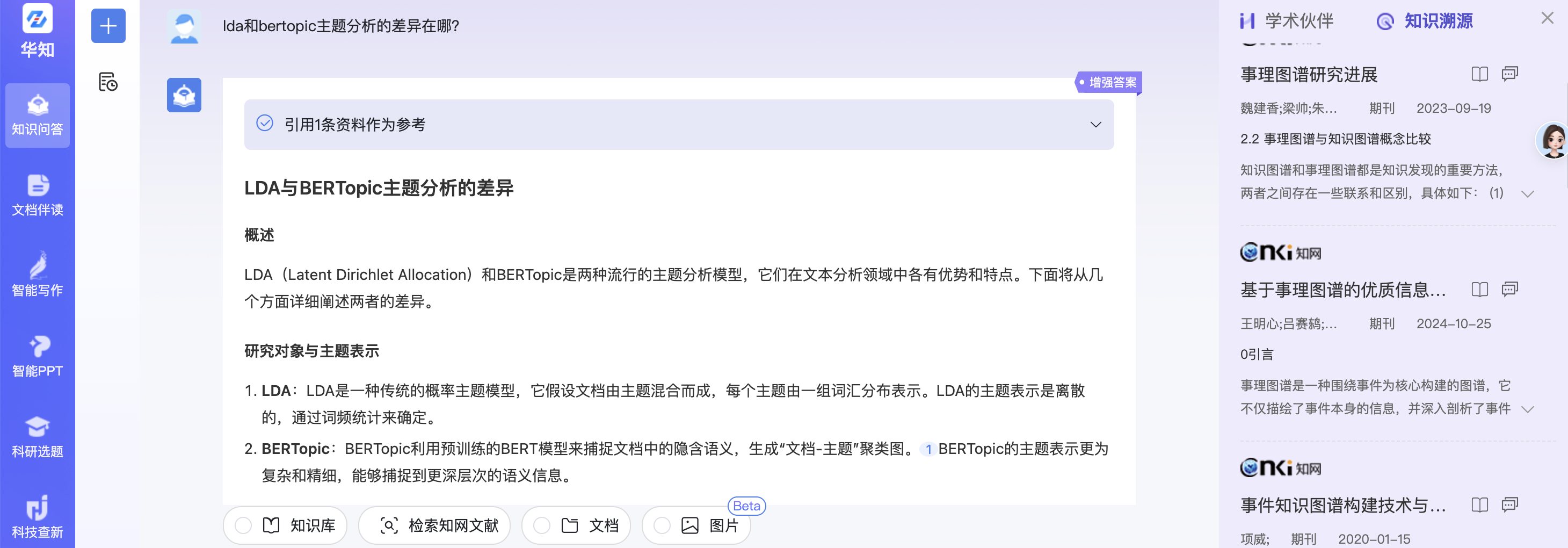

知网的原生结果:
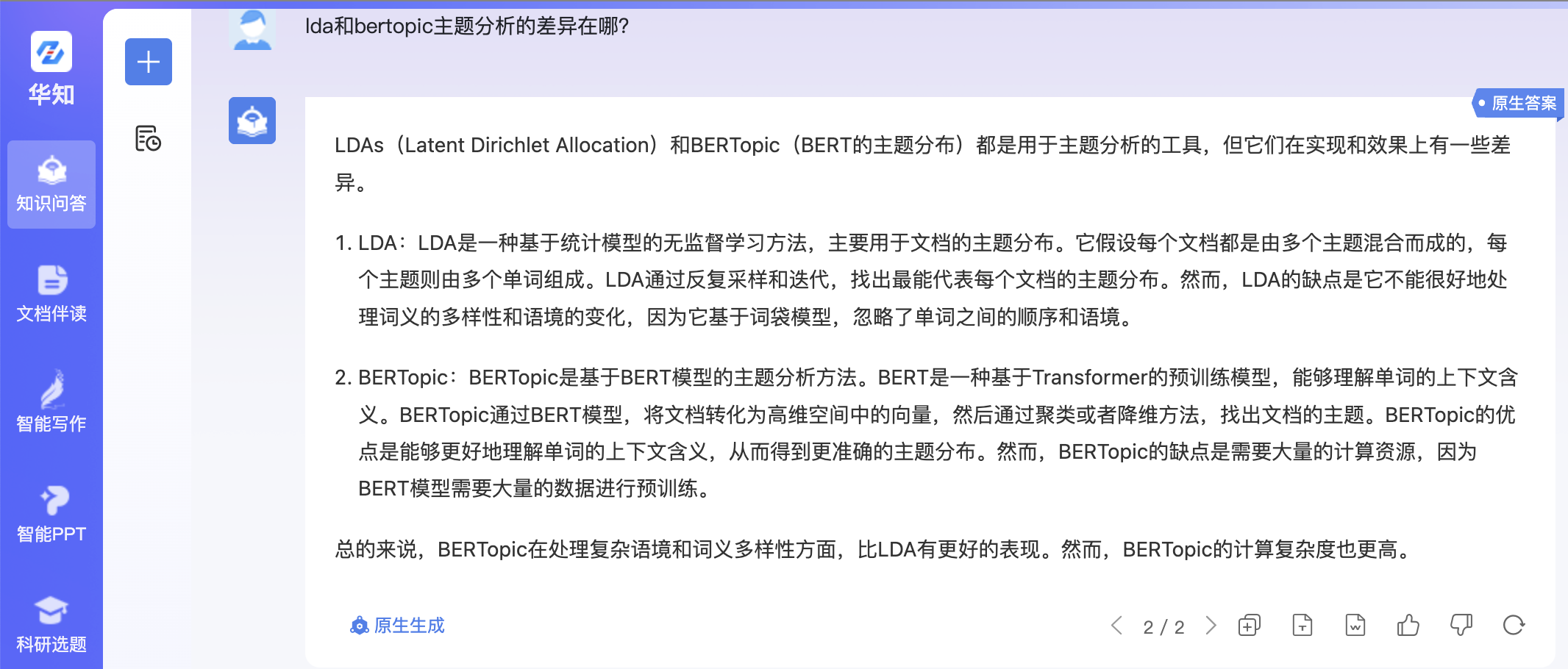
本项目的结果:


可以看到,知网的RAG结果有一定错误,原生结果的信息太少。而本项目的结果显得更为合理。
查询4:那在微博舆情的主题分析中,用哪个更为合适?
知网结果的rag结果:
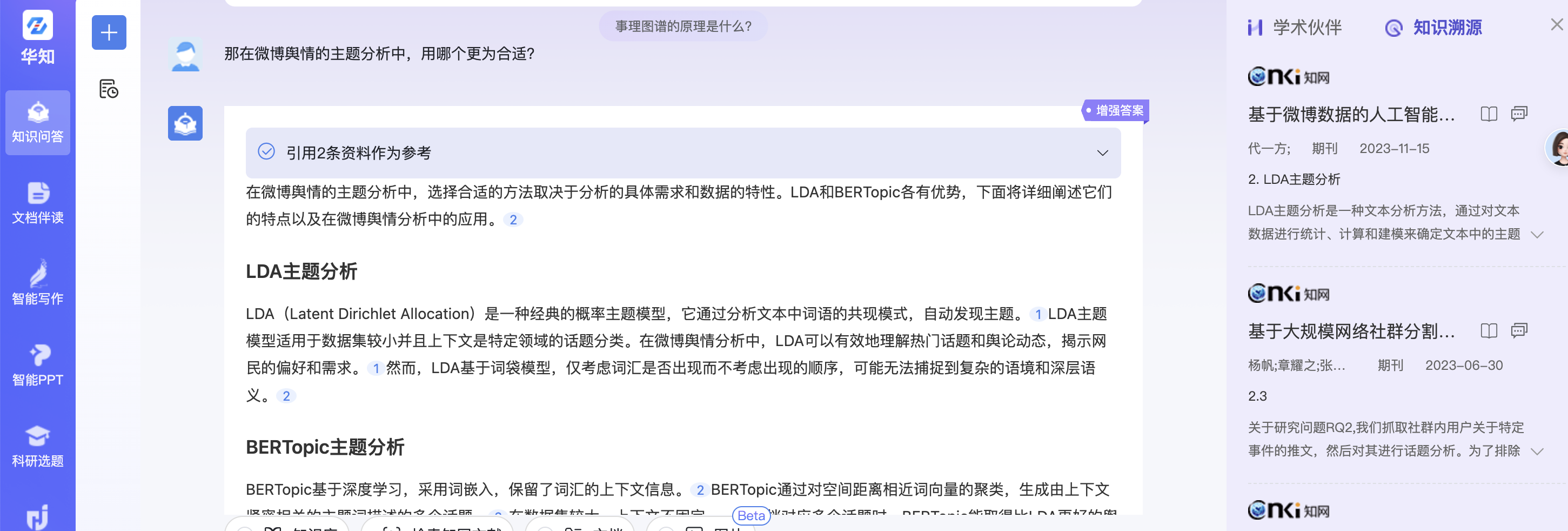
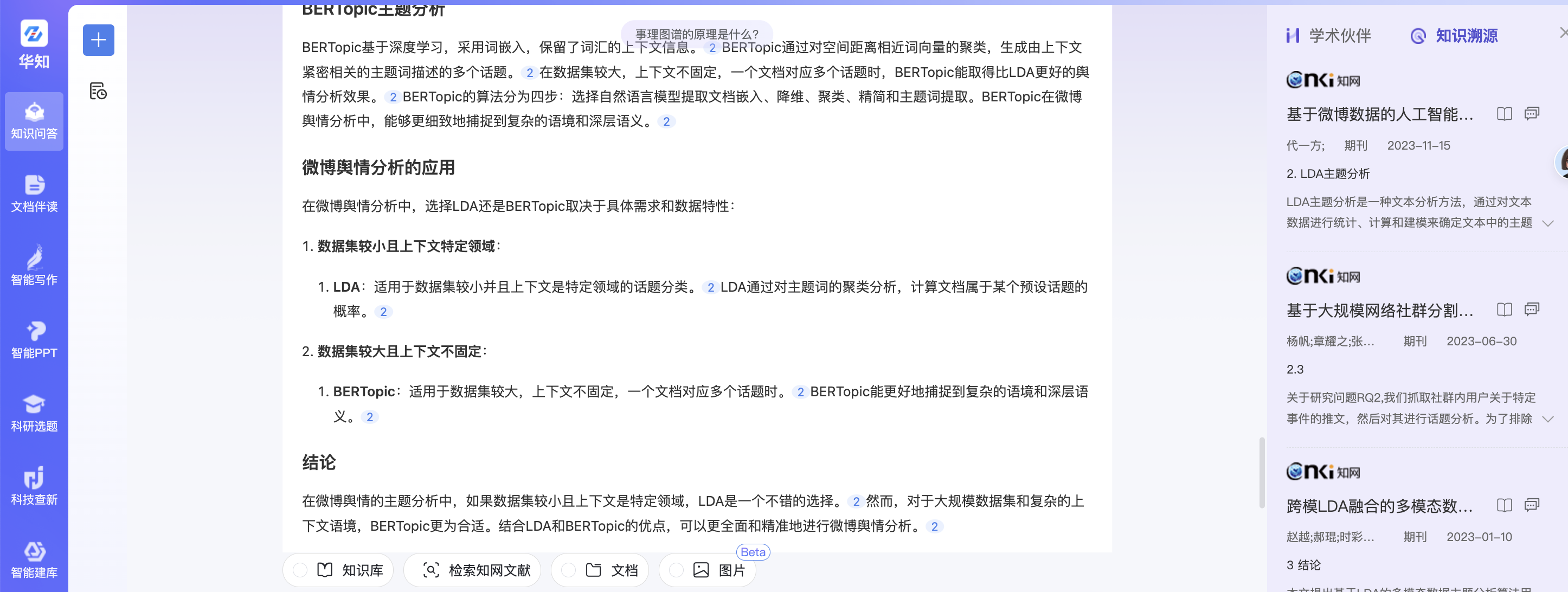
知网的原生结果:

本项目的结果:
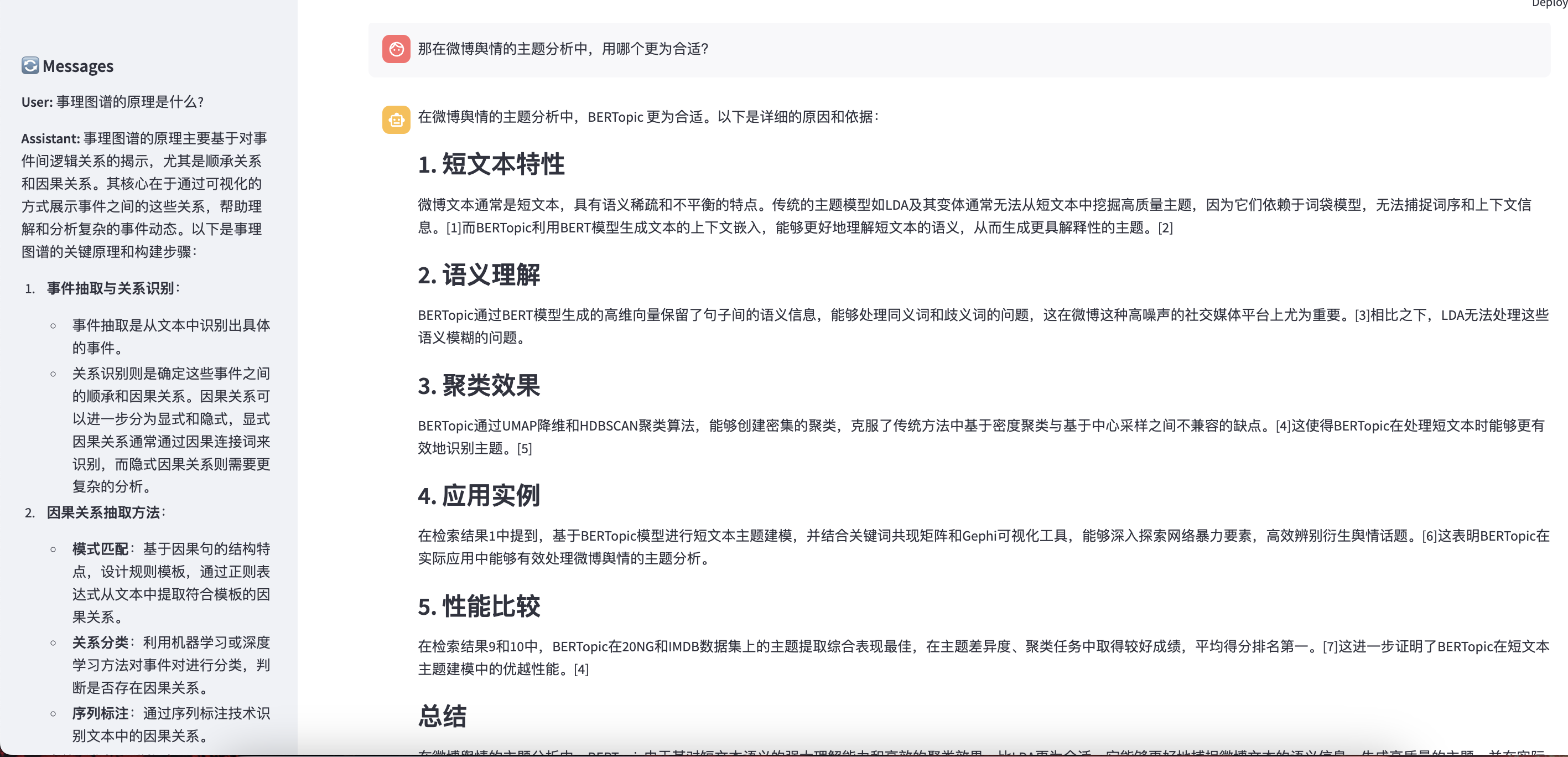

总体来看,本项目的结果更贴近用户的需求。
项目局限及未来发展
①数据量较少:虽然比知网的效果更好,但是毕竟是专一领域的,只有近200篇文献。知网的数据量更大,所以检索时的噪声会更大。未来将持续扩充数据量,囊括不同领域的论文。
②不支持图片输入:事实上,本项目使用开源的向量模型尝试过以图搜文,以文搜图,但是检索出的文或图相关性较差。大概是因为中文论文图片没有相应开源数据集,向量模型没有训练过。后续考虑自己在这类数据上微调,提高召回性能。
③表格展示问题:虽然上面说有表格,但是效果实测没有。这是因为在上下文里添加了表格内容。后续应该选择合适的排版来展示实际表格。
④功能单一问题:现在就只有个问答,这不太low了,除了问答就没有别的形式了?项目已经开发了一个自动添加引用的小工具,给定一个句子,可以自动选择与之最相关的文段作为参考。见:https://www.xiaohongshu.com/discovery/item/676043a9000000000800f87c?source=webshare&xhsshare=pc_web&xsec_token=ABQ5LsXqecpiYj9M8l4rEGeROlBmvLHJ2hkcgvOqMyZBM=&xsec_source=pc_share
未来将开发基于单篇文档的内容理解,类似元宝的深度阅读。